텍스트 분류를 진행하면서 느낀 점은 모델, 학습과 관련된 부분들은 블랙 박스인 부분들이 많아 인과관계들을 파악하기가 정말 어렵다는 것이였다
물론 모델 측면에서도 Loss나 성능 지표, 클래스 가중치, 파라미터 튜닝 등 다뤄볼 부분들은 정말 많지만... 아직 이해도가 너무 낮아서 어떤 부분을 수정하였을 때 모델의 성능이 또는 어떤 영향이 생길지 예상조차 되지 않았다
그래서 데이터 차원에서 어떻게 더 볼 수 있을까 하다가 인코더를 통해 feature vector를 추출하여 분석해보라는 좋은 아이디어를 받아서 진행해보았다
모델의 분류 성능 자체를 넘어서, 모델이 학습한 데이터의 특징 공간(Feature Space)을 분석하여 데이터와 모델의 근본적인 문제점을 파악하는 것
👉 모델의 feature space(특징 공간)를 직접 들여다봐서, 비슷한 감정 유형의 문장들이 실제로 비슷한 임베딩으로 뽑히는지 확인해보는 것이다
즉, 단순히 정확도만 보는 게 아니라 모델이 감정 구조를 “잘 학습하고 있는가”를 시각적으로 검증하자는 접근
1. 최종 목표: 임베딩 공간 분석
- 시도 내용: 모델의 분류기(Classifier) 입력 직전 단계에서 추출된 특징 벡터(Feature Vector)들을 뽑아내어(Embedding), 이 벡터들을 클러스터링(Clustering) 및 시각화(Visualization) 해보는 것이다
- 목적: 모델이 바라보는 텍스트 데이터의 특징 공간에서, 원래의 라벨(긍정/부정, 강한/약한)이 유사한 텍스트들끼리 실제로 가깝게 모여 있는지 확인하여, 다음 두 가지를 점검한다
- 데이터 문제: 라벨이 '중구난방'이라는 말처럼, 데이터 자체의 라벨링이 모호하여 임베딩 공간에서 뚜렷하게 분리되지 않는지.
- 모델 문제: 특징 추출기(Feature Extractor)가 라벨을 구분할 만큼 의미 있는 특징을 잘 학습하지 못했는지.
2. 구체적인 실행 단계
| 단계 | 기술적 내용 | 비고 / 중요성 |
| 특징 추출 | NLP 모델에서 인코더(Encoder) 또는 Feature Extractor 부분만 사용하여 최종 클래스 예측(Classification)이 아닌 문장 임베딩 벡터를 추출. 허깅페이스 등에서 제공하는 extractor를 사용하거나, 기존 모델 클래스에서 분류기 레이어 직전의 출력을 가져와야 한다 |
가장 중요한 핵심: 분류 결과(Class)가 아니라, 특징 공간(Feature Space)을 분석하는 것. |
| 차원 축소 | 특징 벡터는 고차원(수백~수천 차원)이므로, 시각화를 위해 t-SNE나 PCA 같은 기법으로 2D 또는 3D로 차원을 축소 | 주의: 일단 고차원 상태에서 클러스터링을 시도해보고, 시각화할 때만 축소하는 것이 데이터 손실을 최소화하는 방법일 수 있음 |
| 분석 및 검증 | 추출된 저차원 벡터들을 K-means나 DBSCAN 등으로 클러스터링하고, 원래의 라벨(강한 긍정/약한 부정 등)을 색으로 표시하여 시각화 |
핵심 검토 사항: 라벨이 같은 데이터들이 하나의 클러스터로 잘 묶이는지, 아니면 라벨이 다른 데이터들이 섞여있는지. |
| 라벨 조정 (재검증) | 라벨이 너무 세분화(강/약)되어 모호성이 크다면, 이진 분류(Binary Classification) 문제(긍정 vs. 부정)로 단순화하여 특징 공간을 재분석 | 데이터 라벨링의 실효성을 검증하는 중요한 단계 |
1. 허깅페이스에서 Feature Vector 추출 방법
참고하면 좋은 자료
https://chanmuzi.tistory.com/243
[PyTorch] AutoModel vs AutoModelForSequenceClassification 비교하기 (BERT 파헤치기!!)
본 게시물은 NLP 분야에서 가장 많이 사용되는 모델 중 하나인 BERT를 기준으로 작성되었습니다. 드디어 혼자서 아주 간단한 프로젝트에 도전해 볼 기회가 주어져서 밑바닥부터 딥러닝 모델 구조
chanmuzi.tistory.com
주 모델인 BERT가 어떤 모델인지도 알아야한다
17-02 버트(Bidirectional Encoder Representations from Transformers, BERT)
* 트랜스포머 챕터에 대한 사전 이해가 필요합니다.  BERT(Bidire…
wikidocs.net
특징 추출 : Feature Extractor만 사용
- 허깅페이스 모델은 바디와 헤드로 구분되어 있음. 같은 바디를 사용하면서 헤드만 바꾸어 사용할 수도 있기에 각각 따로 불러오거나 커스텀하는 것이 가능하다
- 베이스라인에서 사용하는 허깅페이스 모델(AutoModelForSequenceClassification)은 “feature extractor + classifier”가 결합된 형태
- 하지만 지금 필요한 건 classifier로 가기 전의 hidden representation, 즉 “문장의 의미를 요약한 임베딩 벡터”를 보는 것.
- 그래서 AutoModel이나 AutoModelForMaskedLM처럼 classifier 헤드를 제거한 모델을 불러와서 써야한다
AutoModelForSequenceClassification
“문장 분류까지 되는 완성된 모델”
[Transformer encoder] → [pooler] → [classification head (linear layer + softmax)]
- 즉, feature extractor + classifier가 모두 포함되어 있음.
- 이 모델은 학습 시 loss와 logits을 바로 반환
- 분류 작업(감성 분석, 스팸 탐지 등)에 바로 사용할 수 있도록 세팅되어 있음.
- 결과로 바로 클래스별 점수(logits)를 얻게 됨.
- 이건 softmax만 취하면 곧바로 확률로 변환 가능.
AutoModel
“특징(Feature)만 추출하는 Encoder 모델”
[Transformer encoder only]
- 즉, classifier head가 없음.
- loss나 logits을 계산하지 않고, 문장 또는 토큰 수준의 hidden state만 반환함.
- outputs.last_hidden_state를 통해 각 토큰의 임베딩을 얻고, [CLS] 토큰이나 평균 풀링을 통해 문장 임베딩을 뽑을 수 있음.
둘을 비교해서 표로 정리하면 아래와 같다
| 항목 | AutoModelForSequenceClassification | AutoModel |
| 목적 | 문장 분류 | 피처 추출 |
| 구조 | Transformer + Classifier Head | Transformer만 |
| 출력 | logits (클래스별 점수) | hidden states (임베딩) |
| 사용 시점 | 훈련/추론 단계 | 분석/시각화 단계 |
| 대표 필드 | outputs.logits | outputs.last_hidden_state |
| 학습 목적 | 분류 loss 계산 가능 | feature representation 탐색용 |
간단하게 정리해보면
- AutoModelForSequenceClassification
→ 분류 모델을 학습시키거나 예측할 때 사용. - AutoModel
→ 분류기 앞단의 “문장 표현(embedding)”을 추출할 때 사용. “특징 벡터(feature vector)”는 바로 이 단계
그럼 실제로 어떻게 출력이 나오는지 예시로 확인해보자
AutoModelForSequenceClassification vs AutoModel 비교 예시
from transformers import AutoTokenizer, AutoModelForSequenceClassification, AutoModel
import torch
# 모델 이름
MODEL_NAME = "klue/roberta-base"
# 예시 문장
sentences = ["이 영화 진짜 최고다", "스토리가 너무 지루했다"]
# 1️⃣ 토크나이저
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
inputs = tokenizer(sentences, padding=True, truncation=True, return_tensors="pt")
# 2️⃣ AutoModelForSequenceClassification: classifier 포함
model_cls = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME, num_labels=4)
outputs_cls = model_cls(**inputs)
print("=== AutoModelForSequenceClassification ===")
print("logits shape:", outputs_cls.logits.shape) # (batch_size, num_labels)
print("logits example:", outputs_cls.logits)
# 3️⃣ AutoModel: feature extractor만
model_feat = AutoModel.from_pretrained(MODEL_NAME)
outputs_feat = model_feat(**inputs)
print("\n=== AutoModel ===")
print("last_hidden_state shape:", outputs_feat.last_hidden_state.shape) # (batch_size, seq_len, hidden_dim)
# CLS 토큰 임베딩만 확인
cls_embedding = outputs_feat.last_hidden_state[:, 0, :]
print("CLS embedding shape:", cls_embedding.shape) # (batch_size, hidden_dim)
print("CLS embedding example:", cls_embedding[0][:5]) # 첫 5차원 값만 출력
=== AutoModelForSequenceClassification ===
logits shape: torch.Size([2, 4])
logits example: tensor([[-0.0906, 0.3809, 0.2833, -0.0410],
[-0.0896, 0.3786, 0.2914, -0.0469]], grad_fn=<AddmmBackward0>)
=== AutoModel ===
last_hidden_state shape: torch.Size([2, 8, 768])
CLS embedding shape: torch.Size([2, 768])
CLS embedding example: tensor([ 0.0730, -0.5276, -0.2339, -0.0581, 0.0356], grad_fn=<SliceBackward0>)
- 라벨이 4개라 가정, 배치가 2인 문장 데이터 2개를 넣었을 때
- AutoModelForSequenceClassification 은 2개 문장에 대해 각각의 라벨에 대한 logits 값을 출력한다
- AutoModel 은 문장 각각에 대해 768차원으로 이루어진 문장에 대한 정보를 담은 feature vector를 출력한다
🤔 여기서 들은 의문점. 왜 CLS 임베딩 벡터에서 아래처럼 [ :, 0, : ] 인덱싱을 해줬을까??
outputs_feat.last_hidden_state[:, 0, :]
위에서 확인했듯이 last_hidden_state 의 shape은 (batch_size, seq_len, hidden_dim) 형태이다
- batch_size → 문장 몇 개를 한 번에 넣었는지, 문장의 개수
- seq_len → 가장 긴 문장의 단어 개수, 토큰 길이 (토크나이저로 쪼갠 토큰 수, padding 포함)
- hidden_dim → Transformer가 각 토큰에 대해 만든 임베딩 차원 (예: 768)
여기서 [CLS] 토큰이 어떤 역할을 하는지 이해하는 것이 필요하다
BERT 계열 모델에서는:
- 입력 문장 맨 앞에 특수 토큰 [CLS]를 넣음
- [CLS] 토큰의 hidden state는 문장 전체 의미를 요약하는 벡터로 학습됨
- 그래서 분류 모델에서는 classifier가 [CLS] 벡터만 사용함
즉, [CLS]는 문장-level representation을 담당하는 토큰이다
아래 글들을 보면 더 상세하게 잘 설명되어 있으니 참고할 것
https://seungseop.tistory.com/35
BERT의 [CLS]토큰은 어떻게 sentence의 정보를 담고 있을까?
BERT와 이로부터 파생된 다양한 언어 모델에서는 가장 첫 위치에 문장 공통 토큰인 [CLS]를 두어 해당 위치의 임베딩 결과를 대표 임베딩으로 사용한다. 예컨대, BERT-base 모델은 토큰의 길이가 512이
seungseop.tistory.com
https://jimmy-ai.tistory.com/338
CLS 토큰이란? / 파이썬 BERT CLS 임베딩 벡터 추출 예제
[CLS] 토큰이란? BERT, RoBERTa 등의 언어 모델에서 문장 토큰들이 인코딩된 결과를 활용하는 것이 유용한 경우가 많은데 가장 첫 위치에 문장 공통 토큰인 [CLS]를 두어 해당 위치의 임베딩 결과를 대
jimmy-ai.tistory.com
따라서 인덱싱 [ :, 0, : ] 은 다음을 의미한다
last_hidden_state shape: torch.Size([2, 8, 768])
cls_embedding = outputs_feat.last_hidden_state[:, 0, :]- : → batch 전체 선택
- 0 → sequence 길이에서 첫 번째 토큰 [CLS] 선택
- : → hidden_dim 전체 선택
결과:
cls_embedding.shape = (batch_size, hidden_dim)- 각 문장마다 하나의 feature vector를 얻음
- 이제 이 벡터를 시각화하거나 유사도 계산, clustering 등 활용 가능
입력 문장: "이 영화 진짜 최고다"
토큰화: [CLS] 이 영화 진짜 최고다 [SEP]
| | | | | |
v v v v v v
토큰 임베딩: e_CLS e_이 e_영화 e_진짜 e_최고다 e_SEP
| | | | | |
v v v v v v
+---------------- Transformer Encoder Blocks ----------------+
| Multi-Head Attention + Feed Forward + LayerNorm 반복 |
| 각 토큰 벡터가 문맥 정보를 반영하도록 업데이트 |
+------------------------------------------------------------+
| | | | | |
v v v v v v
last_hidden_state (batch_size, seq_len, hidden_dim)
|
v
CLS 선택: cls_embedding = last_hidden_state[:, 0, :]
shape -> (batch_size, hidden_dim)
|
v
Feature vector / 문장 임베딩
(분류기 입력, 시각화, 클러스터링 등 활용 가능)
선택적으로:
cls_embedding → Linear Layer → Softmax → logits → 클래스
(AutoModelForSequenceClassification)
2. Hard case feature embedding 추출
- “hard case”는 모델이 자주 틀리거나 confidence가 낮은 샘플들을 말한다
- 그 데이터들을 위에서 뽑은 feature extractor에 통과시켜서 임베딩을 얻는다
결과적으로 hard_cases_embeddings.shape는 [num_samples, hidden_dim]이 될 것이다
ex) : [2000, 768]
hard case sample을 뽑는 부분은 여기
https://bh-kaizen.tistory.com/61
텍스트 분류 - Hard Example Mining
텍스트 분류를 진행하던 중, 친구에게 좋은 아이디어를 하나 받았다먼저 교차검증을 돌리면서 각 폴드당 검증셋에 대해 예측한 라벨과 확률값을 저장하면 베이스라인이 원본 전체 데이터셋에
bh-kaizen.tistory.com
위의 글대로 교차 검증을 이용해 전체 데이터를 보면서 예측이 틀린 하드 샘플 데이터 38,713개를 저장해두었다
아래 코드를 통해 하드 샘플들을 pre-trained된 BERT 모델을 거쳐 feature vector를 추출하였다
from transformers import AutoTokenizer, AutoModel
import torch
from torch.utils.data import DataLoader, Dataset
# 1. 모델 및 토크나이저
MODEL_NAME = "kykim/bert-kor-base"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModel.from_pretrained(MODEL_NAME)
model.eval() # 추론 모드로 전환
# 2. 하드 케이스 데이터 (예: list of strings)
hard_cases_texts = hard_df['review_normalized'].tolist() # 38713개 문장
# 3. Dataset / DataLoader 정의
class TextDataset(Dataset):
def __init__(self, texts):
self.texts = texts
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
return self.texts[idx]
dataset = TextDataset(hard_cases_texts)
dataloader = DataLoader(dataset, batch_size=16, shuffle=False)
# 4. Feature 추출
all_embeddings = []
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
with torch.no_grad():
for batch_texts in dataloader:
# 토크나이즈
inputs = tokenizer(batch_texts, padding=True, truncation=True, return_tensors="pt").to(device)
outputs = model(**inputs)
# CLS 벡터 추출
cls_embeddings = outputs.last_hidden_state[:, 0, :] # shape: (batch_size, hidden_dim)
all_embeddings.append(cls_embeddings.cpu())
# 5. 합치기
hard_cases_embeddings = torch.cat(all_embeddings, dim=0)
print("Hard cases embeddings shape:", hard_cases_embeddings.shape)
Hard cases embeddings shape: torch.Size([38713, 768])
- 각 문장마다 768차원으로 이루어진 벡터로 추출하였다
- 임베딩 차원이 768인 이유는 BERT-base 계열 대부분이 hidden_size = 768 을 사용하기 때문
- 아래처럼 내가 사용하는 모델이 몇 차원으로 설정했는지 확인 가능하다
from transformers import AutoModel
model = AutoModel.from_pretrained("kykim/bert-kor-base")
print(model.config.hidden_size) # 768
=> 768
3. 차원 축소 및 클러스터링 시각화
- 768차원은 사람이 볼 수 없으니까, t-SNE나 UMAP, PCA 같은 걸로 축소.
- 축소 후 2D 혹은 3D로 표현해서 점들이 어떻게 모이는지 본다.
t-SNE
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
import umap.umap_ as umap # 설치 필요 / pip install umap-learn
from sklearn.cluster import DBSCAN
# embeddings: torch.Tensor (38404, 768)
embeddings = hard_cases_embeddings.cpu().numpy()
labels = hard_df['label'].values # shape (38404,)
# 라벨별 색상 팔레트
colors = ['#FF6B6B', '#FFD93D', '#6BCB77', '#4D96FF']
# 2D
tsne_2d = TSNE(n_components=2, perplexity=30, n_iter=1000, random_state=42)
emb_2d_tsne = tsne_2d.fit_transform(embeddings)
plt.figure(figsize=(10,8))
for i in np.unique(labels):
plt.scatter(emb_2d_tsne[labels==i,0], emb_2d_tsne[labels==i,1],
label=f'Label {i}', s=10, alpha=0.7, c=colors[i])
plt.title("t-SNE (2D)")
plt.legend()
plt.show()
# 3D
tsne_3d = TSNE(n_components=3, perplexity=30, n_iter=1000, random_state=42)
emb_3d_tsne = tsne_3d.fit_transform(embeddings)
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, projection='3d')
for i in np.unique(labels):
ax.scatter(emb_3d_tsne[labels==i,0], emb_3d_tsne[labels==i,1], emb_3d_tsne[labels==i,2],
label=f'Label {i}', s=10, alpha=0.7)
ax.set_title("t-SNE (3D)")
ax.legend()
plt.show()


PCA
# 2D
pca_2d = PCA(n_components=2, random_state=42)
emb_2d_pca = pca_2d.fit_transform(embeddings)
plt.figure(figsize=(10,8))
for i in np.unique(labels):
plt.scatter(emb_2d_pca[labels==i,0], emb_2d_pca[labels==i,1],
label=f'Label {i}', s=10, alpha=0.7, c=colors[i])
plt.title("PCA (2D)")
plt.legend()
plt.show()
# 3D
pca_3d = PCA(n_components=3, random_state=42)
emb_3d_pca = pca_3d.fit_transform(embeddings)
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, projection='3d')
for i in np.unique(labels):
ax.scatter(emb_3d_pca[labels==i,0], emb_3d_pca[labels==i,1], emb_3d_pca[labels==i,2],
label=f'Label {i}', s=10, alpha=0.7)
ax.set_title("PCA (3D)")
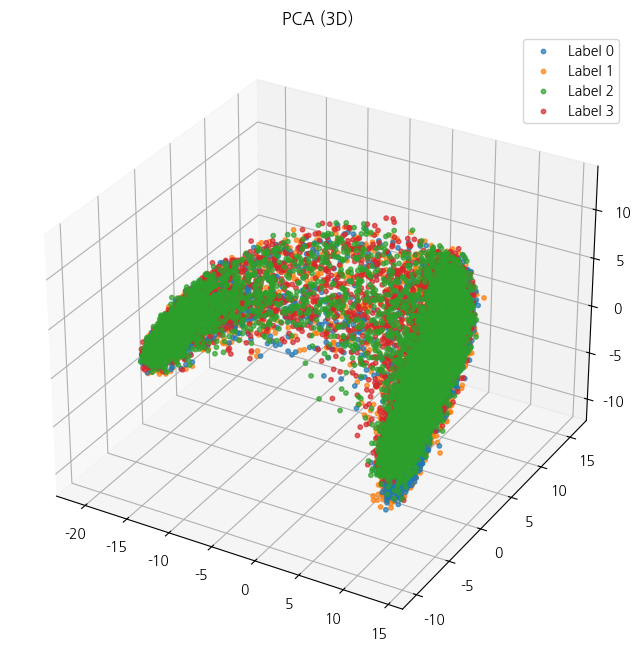
ax.legend()
plt.show()

UMAP
# 2D
umap_2d = umap.UMAP(n_components=2, n_neighbors=15, min_dist=0.1, random_state=42)
emb_2d_umap = umap_2d.fit_transform(embeddings)
plt.figure(figsize=(10,8))
for i in np.unique(labels):
plt.scatter(emb_2d_umap[labels==i,0], emb_2d_umap[labels==i,1],
label=f'Label {i}', s=10, alpha=0.7, c=colors[i])
plt.title("UMAP (2D)")
plt.legend()
plt.show()
# 3D
umap_3d = umap.UMAP(n_components=3, n_neighbors=15, min_dist=0.1, random_state=42)
emb_3d_umap = umap_3d.fit_transform(embeddings)
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, projection='3d')
for i in np.unique(labels):
ax.scatter(emb_3d_umap[labels==i,0], emb_3d_umap[labels==i,1], emb_3d_umap[labels==i,2],
label=f'Label {i}', s=10, alpha=0.7)
ax.set_title("UMAP (3D)")
ax.legend()
plt.show()
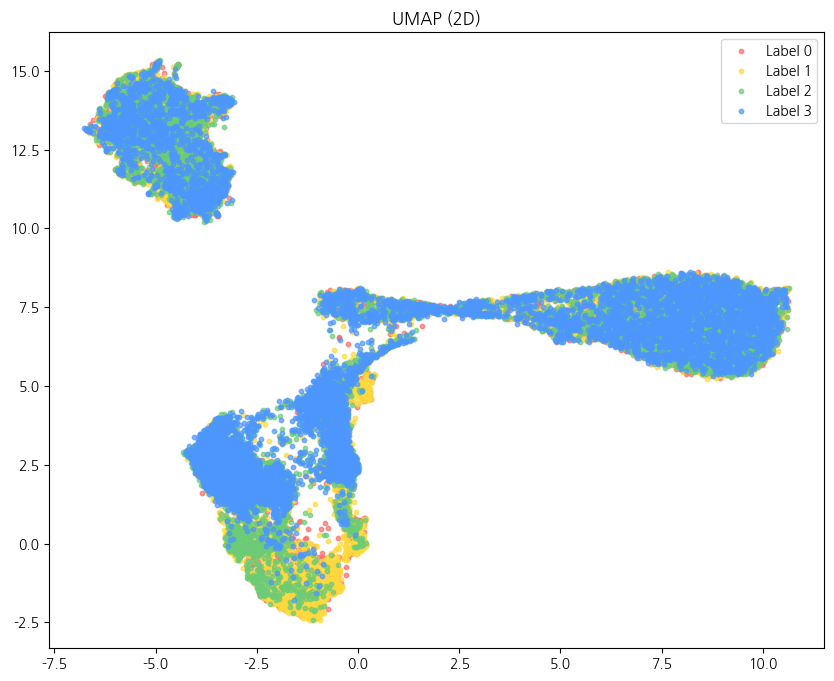
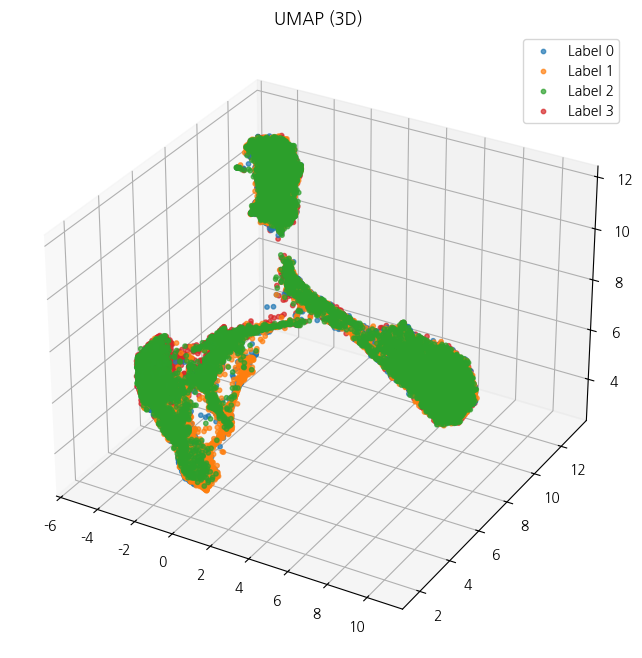
음... 보다시피 라벨의 구분이고 뭐고 없고 그냥 다 하나의 라벨 마냥 뭉쳐있다
혹시 3D plotly로 돌려가면서 보면 레이어로 나눠져있지 않을까...?
3D plotly 시각화 코드
import numpy as np
import plotly.express as px
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
import umap.umap_ as umap
# embeddings: torch.Tensor (38404, 768)
embeddings = loaded_embeddings.cpu().numpy()
labels = hard_df['label'].values # shape (38404,)
label_names = {0: "강한 부정", 1: "약한 부정", 2: "약한 긍정", 3: "강한 긍정"}
# 색상 팔레트 (Plotly용)
colors = ['#FF6B6B', '#FFD93D', '#6BCB77', '#4D96FF']
# --- t-SNE 3D ---
tsne_3d = TSNE(n_components=3, perplexity=30, n_iter=1000, random_state=42)
emb_3d_tsne = tsne_3d.fit_transform(embeddings)
fig_tsne = px.scatter_3d(
x=emb_3d_tsne[:,0], y=emb_3d_tsne[:,1], z=emb_3d_tsne[:,2],
color=[label_names[l] for l in labels],
title="t-SNE (3D) Interactive",
color_discrete_sequence=colors,
opacity=0.7
)
fig_tsne.update_traces(marker=dict(size=3))
fig_tsne.show()
# --- PCA 3D ---
pca_3d = PCA(n_components=3, random_state=42)
emb_3d_pca = pca_3d.fit_transform(embeddings)
fig_pca = px.scatter_3d(
x=emb_3d_pca[:,0], y=emb_3d_pca[:,1], z=emb_3d_pca[:,2],
color=[label_names[l] for l in labels],
title="PCA (3D) Interactive",
color_discrete_sequence=colors,
opacity=0.7
)
fig_pca.update_traces(marker=dict(size=3))
fig_pca.show()
# --- UMAP 3D ---
umap_3d = umap.UMAP(n_components=3, n_neighbors=15, min_dist=0.1, random_state=42)
emb_3d_umap = umap_3d.fit_transform(embeddings)
fig_umap = px.scatter_3d(
x=emb_3d_umap[:,0], y=emb_3d_umap[:,1], z=emb_3d_umap[:,2],
color=[label_names[l] for l in labels],
title="UMAP (3D) Interactive",
color_discrete_sequence=colors,
opacity=0.7
)
fig_umap.update_traces(marker=dict(size=3))
fig_umap.show()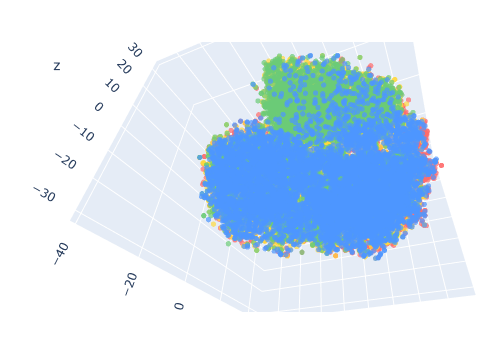

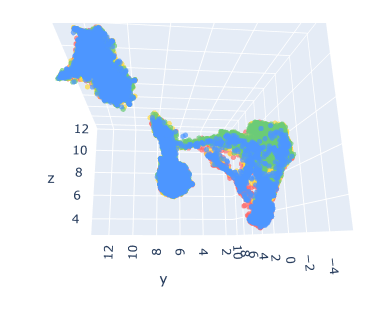
어림도 없지!!
파란색 3번 라벨, 강한 부정이 전체적으로 퍼져있고 그나마 초록색 2번 강한 긍정이 조금이나마 분리가 되는 것으로 보인다
그럼 틀린 데이터들이 아니라 잘 맞추는 데이터들, 높은 확률로 정답 라벨을 맞춘 데이터들을 사용하면 과연 클러스터링이 잘 될까?
27만개의 데이터 중 정상 라벨을 90% 이상 확률로 예측한 데이터들은 184,404개

이렇게 보니 하드 케이스와는 달리 라벨별로 어느정도 자리가 잡혀있음을 확인할 수 있다


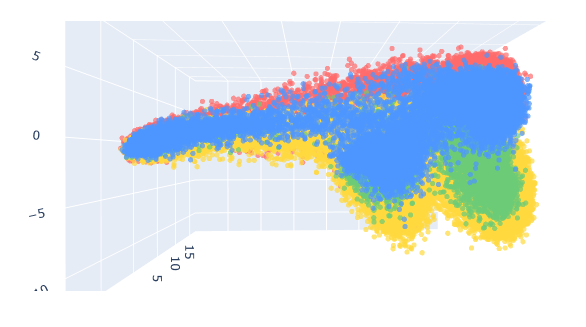

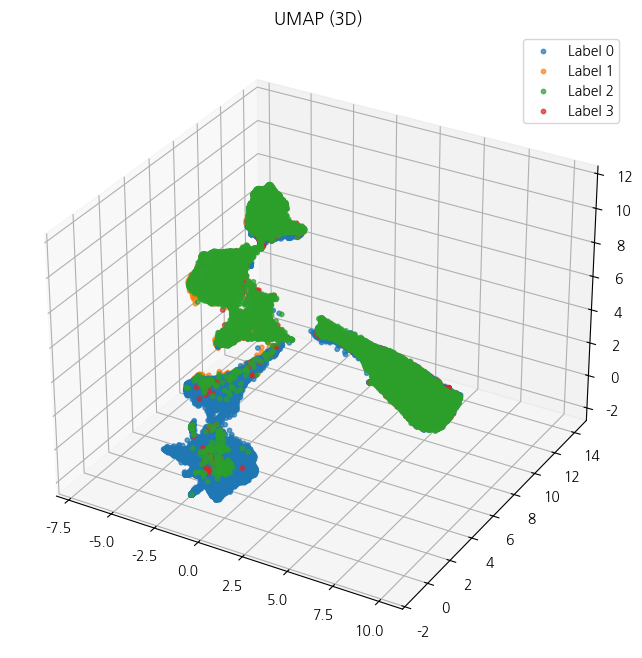
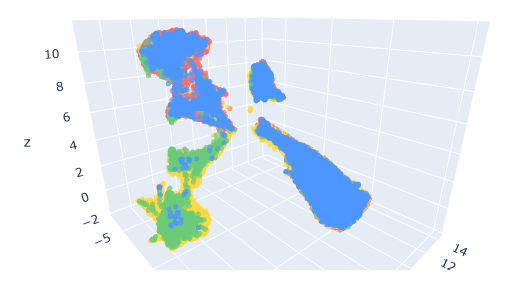
기대했던 것만큼 깔끔하게 분리되진 않지만 시각적으로 유의미한 차이를 확인할 수 있었다
모델의 경우 파인 튜닝이 아닌 pre-trained로 사용해보았으나 파인 튜닝이 된 모델로 봤다면 이 라벨간의 구분을 더 정확하게 해주지 않을까 싶었다
이런 시각화는 학습하기 전 모델이 데이터를 바라보는 시야라고도 할 수 있겠다
4. 라벨별로 구분해서 관찰
한 번에 4개 라벨(강부정·약부정·약긍정·강긍정)을 다 보는 대신:
- 긍정 vs 부정 (이진)
- 약 vs 강 (강도 구분)
이렇게 두 축으로 나눠서 시각화하면 군집이 좀 더 명확하게 나타날 수 있다
현재 라벨:
- 0: 강한 부정 1: 약한 부정 2: 약한 긍정 3: 강한 긍정
두 축을 정의한다:
- X축: 긍정(+) ↔ 부정(-)
- Y축: 강(↑) ↔ 약(↓)
import numpy as np
import matplotlib.pyplot as plt
label_names = {0: "강한 부정", 1: "약한 부정", 2: "약한 긍정", 3: "강한 긍정"}
# 예시: (38404,) 형태의 정답 라벨 벡터
# y = np.array([...])
# 감성 polarity: 부정(0,1)=0 / 긍정(2,3)=1
polarity = np.where(y < 2, 0, 1)
# 감성 intensity: 약(1,2)=0 / 강(0,3)=1
intensity = np.where((y == 0) | (y == 3), 1, 0)
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
# # t-SNE 2D
# tsne_2d = TSNE(n_components=2, perplexity=30, n_iter=1000, random_state=42)
# emb_2d_tsne = tsne_2d.fit_transform(embeddings)
# 🎨 고채도 컬러맵 (직접 정의)
from matplotlib.colors import LinearSegmentedColormap
bright_cmap = LinearSegmentedColormap.from_list("bright_red_green", [
(0.0, "#FF0000"), # pure red
(0.5, "#FFFF00"), # bright yellow
(1.0, "#00FF00") # pure green
])
# ✅ Polarity 시각화 (부정=빨강, 긍정=초록)
plt.figure(figsize=(8, 6))
plt.scatter(
emb_2d_tsne[:, 0], emb_2d_tsne[:, 1],
c=polarity, cmap=bright_cmap, # 고채도 빨강-노랑-초록
s=10, alpha=0.7, edgecolors='none'
)
plt.title("Polarity (Red=부정, Green=긍정)")
plt.xlabel("t-SNE Dim 1")
plt.ylabel("t-SNE Dim 2")
plt.grid(False)
plt.show()
# ✅ Intensity 시각화 (약→강: 밝은→짙은, 더 쨍한 버전)
vivid_viridis = LinearSegmentedColormap.from_list("vivid_viridis", [
(0.0, "#B7E3FF"), # 밝은 하늘색
(0.5, "#4D9BE6"), # 진한 파랑
(1.0, "#1E3A8A") # 매우 짙은 남색
])
plt.figure(figsize=(8, 6))
plt.scatter(
emb_2d_tsne[:, 0], emb_2d_tsne[:, 1],
c=intensity, cmap=vivid_viridis,
s=10, alpha=0.7, edgecolors='none'
)
plt.title("Intensity (Light=약, Dark=강)")
plt.xlabel("t-SNE Dim 1")
plt.ylabel("t-SNE Dim 2")
plt.grid(False)
plt.show()


하드 케이스들의 피쳐 벡터들로 살펴보면 이런 결과가 나온다
사실상 긍정 부정과 강약 모두 많이 섞여있어서 구분이 제대로 되지 않는다
그럼 정답 라벨을 0.9 이상의 높은 확률로 맞춘 데이터들은 어떻게 나올까??


오.. 확실히 분포 자체가 다르다
더 정확하게 비교하기 위해 두 그래프들을 붙여보면 훨씬 더 눈에 잘 들어온다
정답 확률이 90% 이상임에도 불구하고 왼쪽, 위쪽의 클러스터처럼 명확히 구분이 안되는 지점이 존재한다
저기에 분포된 지점의 데이터들을 뽑아내서 분석 후 증강 및 전처리를 해준다면 이것도 유효한 방법이 될 것으로 보인다
그래서 이러한 결과들을 통해 무엇을 알 수 있을까?
그냥 그래프만 찍어보고 끝나면 그건 분석이 아니라 시각화에 불과하다
① 클래스 간 분리도 (Separability)
- 클러스터가 명확히 분리되어 있다면:
모델의 임베딩 공간에서 각 감정 클래스가 잘 구분되고 있다는 뜻.
→ 즉, 이미 모델이 감정의 경계를 잘 학습하고 있다는 의미. - 클러스터가 겹쳐 있다면:
해당 감정들 사이의 표현적 경계가 불분명함.
예: 약한 긍정(2)과 약한 부정(1)이 섞여 있다면, 모델이 문장의 "강약" 표현을 구분하지 못하고 있을 가능성이 높음.
그래프들을 보고서 특히 경계를 잘 구분하지 못하는 라벨에 대해 집중적으로 증강을 시켜주는 것이 유용할 수 있다
또는 그런 라벨들의 텍스트를 확인하여 노이즈나 이상치 등을 확인해 제거해주는 등의 데이터 품질을 개선시킬 수 있다
② 클래스 내부 응집도 (Intra-class compactness)
- 같은 라벨의 샘플들이 밀집되어 있다면:
해당 클래스 내 문장 표현이 일관성 있게 인코딩되고 있음. - 같은 라벨임에도 퍼져 있다면:
해당 감정의 표현 방식이 다양하거나 데이터 품질이 불균일함을 의미.
위와 비슷한 내용이지만 퍼져 있는 특정 클래스의 샘플들을 살펴서, 데이터 노이즈(라벨 오류, 오타, 중의적 표현)를 정제한다
예를 들어 “약한 긍정”이 너무 흩어져 있다면, 강도에 대한 표현 기준이 모호할 수 있다 → 라벨링 기준 재점검.
③ Hard Case의 위치
- 하드케이스(hard samples)를 시각화에 함께 표시하면,
이들이 클러스터 경계 근처에 몰려 있는지, 아니면 특정 영역에 집중되어 있는지 확인 가능 - 경계 근처에 몰려 있다면:
감정 간 경계가 애매한 문장들이 문제의 주 원인 - 특정 영역(예: “약한 긍정” 클러스터 내부 한 부분)에 집중되어 있다면:
해당 표현 유형(예: “좋긴 한데 아쉬움이 있다”)을 모델이 학습하지 못한 것
하드케이스 문장만 따로 모아 데이터 증강(역번역, synonym replacement) 수행.
모델이 약한 감정 경계 표현을 강화하도록 학습.
이 부분까지는 해보지 못했으나 잘 맞춘 샘플 vs 하드 케이스 2개로 시각화를 해보면 또 다른 인사이트를 얻을 수 있지 않을까 싶다
➡️ 예측을 완전히 틀리게 한 하드 케이스들, 대략 16000개에 해당하는 텍스트에 대해 back-translation을 통해 약 16000개 텍스트를 증강시킨 후 베이스라인에 대해 학습시켜보았으나 유의미한 성능 향상은 없었다.
아마 전체 데이터셋 약 27만개 중 일부에 불과해 큰 영향을 미치진 못한 것으로 보인다
④ Pre-trained vs Fine-tuned 비교
- 지금은 pre-trained 임베딩이지만, fine-tuning 후 같은 시각화를 다시 하면
클러스터가 훨씬 더 명확하게 분리되는 걸 볼 수 있을 거야. - 즉, fine-tuning이 “semantic space를 감정별로 재배치하는 과정”임을 시각적으로 검증할 수 있음.
fine-tuning 전후 시각화를 비교하여, 모델 학습 효과를 직관적으로 평가 가능.
“클러스터 분리도 ↑”가 실제 accuracy 향상과 일치하는지도 확인 가능.
이 부분은 학습 후 보고서 작성 등에 시각화 자료로 같이 보여주는 것에도 유용해보인다
명확한 성능 지표와 수치들, 그래프 등으로 보여줄 수 있으나 각 문장들이 좌표상 어디에 위치했으며 모델이 이를 잘 학습하여 얼마나 잘 분류했는지를 더 이해하기 쉽게 보여줄 수 있다
참고 자료
07. 주요 Auto 클래스
## [오토 클래스] ⇒ Transformer 라이브러리에서 모델이나 토크나이저 같은 객체를 이름만으로 자동으로 불러올 수 있게 해주는 편의 클래스 - 허깅페이스에 있는 수많…
wikidocs.net
https://huggingface.co/docs/transformers/ko/model_doc/auto
Auto 클래스
(번역중) 효율적인 학습 기술들
huggingface.co
https://jimmy-ai.tistory.com/539
파이썬 UMAP 차원 축소 및 시각화 예제
안녕하세요.이번 글에서는 python에서 대표적인 차원 축소 알고리즘 중 하나인umap을 통해서 차원 축소를 해보고 시각화로 결과를 살펴보는 예제를 다루어 보겠습니다. 모듈 설치UMAP 시각화를 위
jimmy-ai.tistory.com
'AI' 카테고리의 다른 글
| [Object Detection] Fast R-CNN 살펴보기 (0) | 2025.12.01 |
|---|---|
| [Object Detection] R-CNN 살펴보기 (+SPPNet) (0) | 2025.11.27 |
| 텍스트 분류 - Hard Example Mining (0) | 2025.10.28 |
| VGGNet (ICLR 2015) 요약 및 리뷰 (0) | 2024.01.29 |
