텍스트 분류를 진행하던 중, 친구에게 좋은 아이디어를 하나 받았다
먼저 교차검증을 돌리면서 각 폴드당 검증셋에 대해 예측한 라벨과 확률값을 저장하면 베이스라인이 원본 전체 데이터셋에 대해 문장마다 어떤 답을 얼마의 확률로 예측했는지를 알 수 있게 된다
그리고 못맞춘 문장들에 대해서 이 확률값 p를 1-p 형태로 변환해주면 얼마나 정답을 확신하지 못했는지, 즉 오답에 대해 얼마나 확신했는지를 나타낸다
이를 통해 얻을 수 있는 기대효과로는 자기 정답 클래스에 애매한 확률로 판단하거나 아예 낮은 확률로 완벽하게 정답을 틀리는 케이스들을 수집하여 여기에 대해 핸들링하는, 모델이 데이터를 볼 때 약점을 파악하여 이를 직접적으로 개선할 수 있는 방법이지 않을까 라는 생각이 들었다
이러한 개념을 찾아보니까 Hard Nagative Mining, 모델이 오답을 낸, 예측을 잘못한 어려운 샘플을 추출하는 방법이라 한다
주로 비전쪽에 사용되는 개념이긴 하지만 이러한 개념 자체는 텍스트, 머신 러닝 등에서도 유사하게 활용할 수 있어보인다
사용하는 텍스트 데이터셋에 불균형이 존재하기에 단순히 텍스트 증강만을 적용하려 했으나 여기에 접목시켜 모델이 잘 예측하지 못하는 취약한 데이터에 대해 증강을 해주는 것, Targeted Augmentation 으로 유의미한 성능 향상이 있는지 실험해보려 한다
https://stydy-sturdy.tistory.com/27
[객체 탐지] Hard Negative Mining 이란?
Object Detection task에서 bounding box를 뽑으면 수천 개를 뽑게 된다. 수천 개의 Bounding Box 안에 우리가 찾고자 하는 물체 혹은 객체가 있는 박스가 평균 수십 개 있다고 가정하면 나머지 박스들 즉, 물
stydy-sturdy.tistory.com
OHEM: Training Region-based Object Detectors with Online Hard Example Mining
이번 포스팅에서는 OHEM(Online Hard Example Mining)논문을 리뷰해보겠다.일반적으로 object detection시에 배경영역에 해당하는 region proposals의 수가 더 많아 클래스 불균형이 발생하고, 이 문제를 해결하기
velog.io
1. 핵심 개념
- 모델이 약한 데이터 (=hard sample) 를 찾아낸다.
→ 정답 클래스 확률(p_true)이 낮은 샘플 = 모델이 불확실하거나 틀린 샘플 - 그 샘플들을 집중 증강한다.
→ Synonym 교체, 번역 후 복원, LLM을 이용한 문장 재작성 등으로 다양화 - 다시 학습시켜 성능 비교
→ 전체 증강보다 효율적이고, 모델 약점을 보완함
2. 구현 절차
Step 1. 교차 검증 예측 결과 얻기 (Out-of-Fold Prediction)
- 모델 학습 후, 교차검증을 통해 각 샘플의 예측 확률을 얻는다.
- 이를 통해 “해당 샘플을 학습에 사용하지 않은 fold”에서의 예측 결과를 확보 → 과적합 방지
아래는 허깅페이스의 모델 및 토크나이저를 사용하여 폴드마다 모델을 새로 불러와서 학습시키고 검증셋에 대한 예측 라벨과 확률을 저장한다
교차검증에는 시간이 오래 걸리기 때문에 매번 돌릴 수 없으므로 csv로 저장해두는 것이 좋다
# ==========================================================
# 3. 모델 및 토크나이저 설정
# ==========================================================
MODEL_NAME = "kykim/bert-kor-base" # 대회 허용 모델 중 하나
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
# ==========================================================
# 4. K-Fold 설정
# ==========================================================
NUM_FOLDS = 10
RANDOM_STATE = 42
skf = StratifiedKFold(n_splits=NUM_FOLDS, shuffle=True, random_state=RANDOM_STATE)
oof_preds = np.zeros(len(df), dtype=int)
oof_probs = np.zeros((len(df), 4)) # 감정 클래스 4개
fold_accuracies = []
# ==========================================================
# 5. Fold별 학습 및 OOF 예측
# ==========================================================
for fold, (train_idx, val_idx) in enumerate(skf.split(X, y)):
print(f"\n===== Fold {fold+1} / {NUM_FOLDS} =====")
X_train, X_val = [X[i] for i in train_idx], [X[i] for i in val_idx]
y_train, y_val = [y[i] for i in train_idx], [y[i] for i in val_idx]
train_dataset = ReviewDataset(X_train, y_train, tokenizer)
val_dataset = ReviewDataset(X_val, y_val, tokenizer)
test_dataset = ReviewDataset(test_texts, labels=None, tokenizer=tokenizer)
model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME, num_labels=4)
training_args = TrainingArguments(
output_dir=f"./results/fold_{fold+1}",
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
metric_for_best_model="accuracy",
greater_is_better=True,
save_total_limit=1,
per_device_train_batch_size=128,
per_device_eval_batch_size=256,
num_train_epochs=3,
learning_rate=5e-5,
warmup_steps=500,
weight_decay=0.05,
seed=RANDOM_STATE,
fp16=torch.cuda.is_available(),
logging_strategy="epoch", # ← 로그 남기는 주기 지정
report_to="none", # ← wandb나 tensorboard로 안 보낼 경우
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
compute_metrics=compute_metrics,
)
trainer.train()
# 검증 데이터 예측
preds_output = trainer.predict(val_dataset)
preds = np.argmax(preds_output.predictions, axis=1)
probs = torch.nn.functional.softmax(torch.tensor(preds_output.predictions), dim=1).numpy()
# OOF 결과 저장
oof_preds[val_idx] = preds
oof_probs[val_idx] = probs
acc = accuracy_score(y_val, preds)
fold_accuracies.append(acc)
print(f"Fold {fold+1} Accuracy: {acc:.4f}")
# 테스트셋 예측
print(f"→ Fold {fold+1} Test inference 중...")
test_output = trainer.predict(test_dataset)
test_probs = torch.nn.functional.softmax(torch.tensor(test_output.predictions), dim=1).numpy()
test_preds = np.argmax(test_probs, axis=1)
# CSV로 저장
test_pred_df = pd.DataFrame({
"ID": test_ids,
"pred": test_preds
})
test_prob_df = pd.DataFrame(test_probs, columns=[f"class_{i}_prob" for i in range(4)])
test_prob_df.insert(0, "ID", test_ids)
test_pred_df.to_csv(f"test_fold_{fold+1}_predictions.csv", index=False)
test_prob_df.to_csv(f"test_fold_{fold+1}_probabilities.csv", index=False)
print(f"✅ Fold {fold+1} 테스트 예측 결과 저장 완료.")
# ==========================================================
# 6. OOF 성능 확인
# ==========================================================
# 원본 데이터와 예측을 비교하여 폴드의 전체적인 성능을 체크함
oof_acc = accuracy_score(y, oof_preds)
print(f"\n✅ Overall OOF Accuracy: {oof_acc:.4f}")
print(f"Fold Accuracies: {fold_accuracies}")✅ Overall OOF Accuracy: 0.8605
Fold Accuracies: [0.8553166763509588, 0.860945671121441, 0.8615630447414294, 0.8647951772225451, 0.8609819872167345, 0.860691458454387, 0.8604009296920395, 0.8593789722171782, 0.858979480660977, 0.8622480479389868]
✅ OOF 결과 포함한 CSV 저장 완료
총 38404개의 hard case 탐지됨
- 아래 원본 데이터와 예측을 비교해서 Accuracy를 확인하는 부분도 있다. 이번 10폴드 진행했을 때 Accuracy는 0.86 정도
- 이건 베이스라인이 원본 데이터 전체에 대해 어느 정도의 정확도로 예측했는지 참고하는데 사용하면 좋을 것 같다
Step 2. Hard Sample 식별 및 분석
자기 정답 클래스의 확률(p_true)이 낮을수록 모델이 불확실한 샘플이다.
이때 1 - p_true 값이 클수록 “어려운 샘플”.
# ==========================================================
# 7. Hard Case 탐색
# ==========================================================
df["oof_pred"] = oof_preds
df["is_correct"] = (df["label"] == df["oof_pred"])
df["oof_confidence"] = oof_probs.max(axis=1)
df.to_csv("./oof_results_with_confidence.csv", index=False)
print("✅ OOF 결과 포함한 CSV 저장 완료")
# consistently 틀린 샘플만 필터링
hard_cases = df[~df["is_correct"]].sort_values("oof_confidence")
print(f"\n총 {len(hard_cases)}개의 hard case 탐지됨")
hard_cases[["ID", "review_normalized", "label", "oof_pred", "oof_confidence"]].head(10)- Hard Case 탐색의 경우 확률이 높고 낮음과 상관없이 답을 틀린 것에 대해서만 적용하여 전체 중 몇 개를 틀렸는지를 체크한다
p_true = oof_probs[np.arange(len(df)), df["label"].values]
df["p_true"] = p_true
df["hardness"] = 1 - df["p_true"]
p_true = oof_probs[np.arange(len(df)), df["label"].values]- 이 한 줄은 각 샘플에 대해, 정답 클래스에 해당하는 확률값을 뽑아낸 것
- oof_probs 에는 교차 검증을 하면서 검증셋 라벨마다의 예측값이 담겨있음
- oof_probs[i] → 샘플 i에 대한 모델의 softmax 확률 예측 벡터 (예: [0.1, 0.7, 0.1, 0.1])
- df["label"].values[i] → 샘플 i의 실제 정답 클래스 (예: 1)
- 따라서 oof_probs[i, df["label"][i]] → 모델이 정답 클래스에 할당한 확률 (여기서는 0.7)
- 만약 모델이 잘못 예측했다면 이 확률이 매우 낮게 나오기도 함
p_true
- 모델이 각 샘플의 “진짜 정답 클래스”에 얼마나 확신을 가졌는지를 나타내는 값
- 값의 범위는 0~1이며, 1에 가까울수록 모델이 정답을 강하게 확신했다는 뜻
hardness
- 모델이 정답에 대해 얼마나 “어려워했는가”
- 모델이 정답 확률 (p_true) 을 높게 예측하면 → p_true ↑ → hardness ↓ (쉬운 샘플)
- 모델이 정답 확률 (p_true) 을 낮게 예측하면 → p_true ↓ → hardness ↑ (어려운 샘플)
- 0.9 → 매우 어려운 샘플 (거의 틀릴 뻔했거나 실제로 틀렸을 확률이 높음)
- 0.5 → 중간 정도로 불확실
- 0.1 → 매우 쉬운 샘플 (거의 확실하게 맞춤)
- p_true, 1-p_ture 값을 계산 후 데이터 프레임에 추가
- 최종적으로 아래와 같은 형태로 기존의 데이터셋에 예측 라벨, 정답 여부, 확률값들과 예측의 어려움 등이 추가되었다
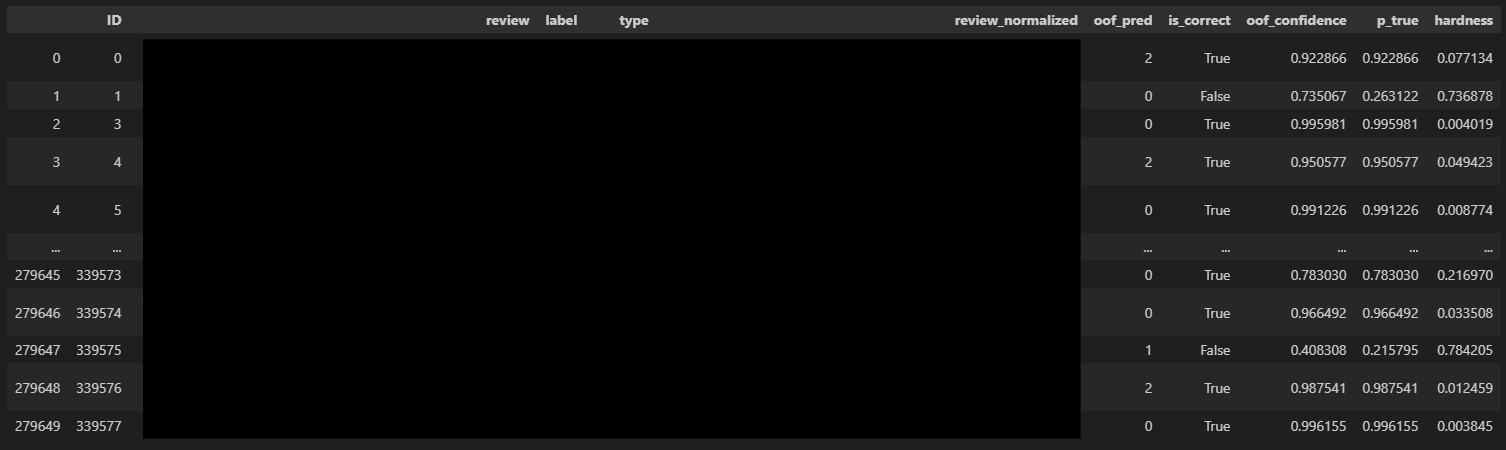
- 이때, 예를 들어 p_true < 0.4 또는 상위 20% 정도 등 어느 정도까지 “hard” 샘플로 간주할 것인지 기준을 정해야한다
- 이 Hard Sample을 단순 수집하는 선에서 끝나선 안된다
- 어떤 클래스 분포를 띄고 있는지, 어떤 문장, 단어들로 이루어져 있는지 분석을 해주는 것이 필요하다
# 상위 20% hard samples
threshold = df["hardness"].quantile(0.8)
hard_top = df[df["hardness"] >= threshold].sort_values("hardness", ascending=False)
hard_top.head(20)
threshold = df["hardness"].quantile(0.8)- hardness 분포에서 상위 20% 경계값 (80번째 백분위수) 를 의미
- 즉, hardness 값이 전체 중 상위 20% 안에 들어가는 기준선을 찾는 것

- 틀리게만 예측한 하드케이스는 총 38404개, hardness를 높은 순으로 상위 20%는 총 55072개에 달한다
- 전체 데이터셋이 대략 27만개임을 생각하면 꽤 적지않은 샘플들을 제대로 맞추지 못한다고 볼 수 있다
- 그 중 가장 hardness가 높은 순부터 20개를 불러왔다
- 첫번째 문장은 정답이 0번인데 2번으로 잘못 예측하였다
- 그리고 2번으로 잘못 예측한 확률은 무려 0.99... 정답을 예측한 확률은 0.000036으로 매우매우매우 낮게 예측했기에 모델이 어렵게 보았음을 확인할 수 있다
그럼 못 맞추는 상위 20% 하드 샘플에서 클래스별 개수, 분포는??

| label | count |
| 0 | 12341 |
| 1 | 12460 |
| 2 | 17771 |
| 3 | 12500 |
Step 3. Hard Sample 기반 증강
텍스트 증강에는 여러 가지 방법들이 존재한다
그 중 일부 사용한 방법들만 간단하게 정리하였다
(A) 번역 기반 증강 (Back-translation)
- 한국어 → 영어 → 한국어 번역
- 문장 구조와 일부 단어 변경 → 의미 유지
- 허깅페이스에 있는 다양한 번역 모델들 활용 가능
- 샘플의 길이가 너무 짧은 케이스는 번역이 안되고 데이터 품질이 더 저하될 수 있기에 필터링해주는 것이 좋을 것으로 보인다
- ex) 2.3 / 안과 겉 / 에휴 등등..
필터링
(1) 샘플 길이 기준
- 짧은 문장, 한두 단어만 있는 리뷰는 Back-Translation 효과 거의 없음 → 의미 훼손 가능
- 예: 길이 5~10자 이하(토큰 기준) 샘플은 증강 제외
min_len = 10 # 토큰 수 기준
hard_top_filtered = hard_top[hard_top['review_normalized'].str.len() >= min_len]
(2) 모델 확신도(confidence) 기준
- 이미 맞춘 샘플인데 confidence가 높다면 증강 필요 없음
- 예: confidence < 0.7 → 증강 후보
hard_top_filtered = hard_top_filtered[hard_top_filtered['oof_confidence'] < 0.7]
(3) 모델 예측 어려움 기준
- 예측이 어려운 기준값, hardness가 일정 기준보다 높을 때 더 학습을 잘 할 수 있게끔 유사한 데이터를 추가해주면 유효할 것으로 판단
- 예: hardness > 0.6 → 증강 후보
hard_top_filtered = hard_top_filtered[hard_top_filtered['hardness'] > 0.6]
(4) 클래스 비율 기준
- 소수 클래스 우선 증강: 1(약한 부정)과 3(강한 긍정)
hard_top_filtered = hard_top_filtered[hard_top_filtered['label'].isin([1, 3])]
아래는 한국어 -> 영어 -> 한국어로 번역을 거쳐 증강시키는 샘플 코드이다
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
# 모델 및 토크나이저 로드
mbart_model_name = "facebook/mbart-large-50-many-to-many-mmt"
model = MBartForConditionalGeneration.from_pretrained(mbart_model_name)
tokenizer = MBart50TokenizerFast.from_pretrained(mbart_model_name)
import torch
def mbart_translate(texts, src_lang="ko_KR", tgt_lang="en_XX"):
translated_texts = []
for text in texts:
tokenizer.src_lang = src_lang
encoded = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
generated_tokens = model.generate(**encoded, forced_bos_token_id=tokenizer.lang_code_to_id[tgt_lang])
translated_texts.append(tokenizer.decode(generated_tokens[0], skip_special_tokens=True))
return translated_texts
# 예시 하드 샘플
hard_samples = [
"이 문장은 감정 분석 모델을 테스트하기 위한 예시입니다.",
"모델이 잘 맞추지 못하는 하드 케이스를 분석해야 합니다."
]
# 한국어 → 영어
ko2en = mbart_translate(hard_samples, src_lang="ko_KR", tgt_lang="en_XX")
print("한국어 → 영어:", ko2en)
# 영어 → 한국어 (Back-translation)
back_translated = mbart_translate(ko2en, src_lang="en_XX", tgt_lang="ko_KR")
print("Back-translation (한국어 → 영어 → 한국어):", back_translated)
한국어 → 영어:
['This sentence is an example of testing an emotion-analysis model.',
"You have to analyze the hard case where the model doesn't fit."]
Back-translation (한국어 → 영어 → 한국어):
['이 문장은 감정 분석 모델을 시험하는 예입니다.',
'모델이 맞지 않는 어려운 경우를 분석해야 합니다.']- 보다시피 유사한 문장이 출력으로 나온 것을 확인할 수 있다
- 위의 예제 코드는 얼마 안되는 문장들이라서 간단하게 for문 돌리지만 실제로는 천에서 만단위의 문장들을 돌려야하기 때문에 저렇게 쓰면 안된다..
필터링 및 Back-translation 적용 코드
from transformers import MBartForConditionalGeneration, MBart50Tokenizer
import torch
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
import pandas as pd
# ==========================================================
# 1. 모델 및 토크나이저 로드
# ==========================================================
mbart_model_name = "facebook/mbart-large-50-many-to-many-mmt"
model = MBartForConditionalGeneration.from_pretrained(mbart_model_name, torch_dtype=torch.float16)
tokenizer = MBart50Tokenizer.from_pretrained(mbart_model_name)
model = torch.compile(model)
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
# ==========================================================
# 2. Dataset 정의
# ==========================================================
class TextDataset(Dataset):
def __init__(self, texts):
self.texts = texts
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
return self.texts[idx]
# ==========================================================
# 3. Collate 함수 (배치 단위 토크나이징)
# ==========================================================
def collate_fn(batch_texts, src_lang, tokenizer, device):
tokenizer.src_lang = src_lang
encoded = tokenizer(
batch_texts,
return_tensors="pt",
padding=True,
truncation=True,
max_length=128
)
encoded = {k: v.to(device) for k, v in encoded.items()}
return encoded
# ==========================================================
# 4. DataLoader 기반 번역 함수
# ==========================================================
def mbart_translate_dataloader(texts, src_lang="ko_KR", tgt_lang="en_XX", batch_size=32, num_workers=2):
dataset = TextDataset(texts)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers)
translated_texts = []
for batch_texts in tqdm(dataloader, desc=f"Translating {src_lang} → {tgt_lang}"):
encoded = collate_fn(batch_texts, src_lang, tokenizer, device)
with torch.no_grad():
generated_tokens = model.generate(
**encoded,
forced_bos_token_id=tokenizer.lang_code_to_id[tgt_lang],
max_length=256
)
decoded = [tokenizer.decode(t, skip_special_tokens=True) for t in generated_tokens]
translated_texts.extend(decoded)
return translated_texts
# ==========================================================
# 5. 필터링 + 증강 함수 (DataLoader 기반)
# ==========================================================
def augment_hard_samples_filtered_dataloader(df_hard, n_aug=1,
min_len=10, max_confidence=0.7,
target_labels=[1,3], top_hardness=0.7,
batch_size=32, num_workers=2):
"""
df_hard: 하드 샘플 데이터프레임 (review_normalized, label, oof_confidence, hardness 포함)
n_aug: 각 샘플당 생성할 증강 수
"""
# 필터링
df_filtered = df_hard[
(df_hard['label'].isin(target_labels)) &
(df_hard['oof_confidence'] <= max_confidence) &
(df_hard['review_normalized'].str.len() >= min_len)
]
threshold = df_filtered['hardness'].quantile(top_hardness)
df_filtered = df_filtered[df_filtered['hardness'] >= threshold]
print(f"증강 대상 샘플 수: {len(df_filtered)}")
aug_texts = []
aug_labels = []
for _ in tqdm(range(n_aug), desc="Augmentation rounds"):
ko_texts = df_filtered['review_normalized'].tolist()
# 한국어 → 영어 → 한국어
en_texts = mbart_translate_dataloader(ko_texts, src_lang="ko_KR", tgt_lang="en_XX",
batch_size=batch_size, num_workers=num_workers)
back_texts = mbart_translate_dataloader(en_texts, src_lang="en_XX", tgt_lang="ko_KR",
batch_size=batch_size, num_workers=num_workers)
aug_texts.extend(back_texts)
aug_labels.extend(df_filtered['label'].tolist())
return aug_texts, aug_labels
# ==========================================================
# 6. 예시 사용
# ==========================================================
# hard_top_filtered: 기존 필터링 후 하드 샘플 데이터프레임
aug_texts, aug_labels = augment_hard_samples_filtered_dataloader(
df_hard=hard_top,
n_aug=1,
min_len=10,
max_confidence=0.7,
target_labels=[1,3],
top_hardness=0.7,
batch_size=128,
num_workers=8 # CPU 코어 여유 있으면 4~8 추천
)
print(f"증강 완료 샘플 수: {len(aug_texts)}")
print("예시 증강 문장:", aug_texts[:5])
증강 대상 샘플 수: 3889
Translating ko_KR → en_XX: 100%|██████████| 31/31 [15:53<00:00, 30.76s/it]
Translating en_XX → ko_KR: 100%|██████████| 31/31 [08:43<00:00, 16.87s/it]
Augmentation rounds: 100%|██████████| 1/1 [24:36<00:00, 1476.75s/it]
증강 완료 샘플 수: 3889
예시 증강 문장:
['아시나요? plot 을 보실 수 있죠. 그는 멍청이가 아니라, 아들이 있고, 조카가 있고, 아기가 있습니다.',
'모든 것이 좋았고, 끝도 좋았습니다.',
'다른 끔찍한 블럭버스터보다 더 낫고, 더 생각하게 해주고, 제 형이 7년 동안 Phuket에서 살았던 것을 떠올리게 해주고, 푸에르토리코로 가는 것을 떠올리게 해주죠.',
'그렇지 않다면, 저는 멋진 젊은 브래드 피트를 무장복을 입고 매력적이고 외향적인 캐릭터로 입을 것입니다.',
'유일한 단점은 이 영화가 너무 짧다는 것입니다.']
- 위의 코드를 통해 필터링된 Hard Case는 3889건
- 한국어 ➡️ 영어 ➡️ 한국어로 2번의 번역을 거치는데 24분 정도가 걸렸다
- 증강 결과의 일부를 확인해보면 번역했을 때 특유의 문체와 느낌이 있어서 너무 많이 증강할 경우 번역체에 대해 편향이 커져서 구어체와 비문에 대한 예측이 떨어질 확률이 커지므로 이 부분 주의해야 한다
(B) LLM 기반 증강 (합성 생성)
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch, pandas as pd
from sentence_transformers import SentenceTransformer, util
import torch.nn.functional as F
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from tqdm import tqdm
# =========================
# 설정
# =========================
PROMPT_TEMPLATE = """다음 문장을 자연스럽게 의미가 같은 다른 표현으로 2가지 써줘.
구어체나 일상적인 표현을 사용하고, 문법적으로 약간 틀려도 자연스러우면 좋아.
원문: {sentence}
"""
LLM_MODEL = "spow12/Ko-Qwen2-7B-Instruct"
CLS_MODEL = "./best_model"
# CLS_MODEL = "klue/roberta-base"
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
BATCH_SIZE_LLM = 8 # LLM 배치 크기
BATCH_SIZE_SBERT = 16 #SBERT, 감성 분류 배치 크기
# =========================
# 모델 로드
# =========================
tokenizer_llm = AutoTokenizer.from_pretrained(LLM_MODEL)
model_llm = AutoModelForCausalLM.from_pretrained(
LLM_MODEL,
torch_dtype=torch.float16,
device_map="auto",
offload_folder="./offload" # CPU로 임시 오프로드
)
sbert = SentenceTransformer("jhgan/ko-sroberta-multitask").to(DEVICE)
tokenizer_cls = AutoTokenizer.from_pretrained(CLS_MODEL)
model_cls = AutoModelForSequenceClassification.from_pretrained(CLS_MODEL).to(DEVICE)
# =========================
# 함수 정의
# =========================
def generate_paraphrases_batch(sentences, num_return=3):
prompts = [PROMPT_TEMPLATE.format(sentence=s) for s in sentences]
inputs = tokenizer_llm(prompts, padding=True, truncation=True, return_tensors="pt").to(model_llm.device)
outputs = model_llm.generate(
**inputs,
max_new_tokens=128,
temperature=0.9,
top_p=0.9,
do_sample=True,
num_return_sequences=num_return,
eos_token_id=tokenizer_llm.eos_token_id
)
decoded = tokenizer_llm.batch_decode(outputs, skip_special_tokens=True)
# 결과를 2차원 리스트로 변환: [ [문장1, 문장2, ...], [문장1, ...], ... ]
result_batch = []
for i in range(0, len(decoded), num_return):
result_batch.append([r.split("원문:")[-1].strip() for r in decoded[i:i+num_return]])
return result_batch
def is_similar_batch(originals, candidates, threshold=0.80):
# originals: list of str
# candidates: list of str
orig_emb = sbert.encode(originals, batch_size=BATCH_SIZE_SBERT, convert_to_tensor=True)
cand_emb = sbert.encode(candidates, batch_size=BATCH_SIZE_SBERT, convert_to_tensor=True)
sim_matrix = util.cos_sim(orig_emb, cand_emb)
return sim_matrix.diagonal() >= threshold # 각 후보와 원문 유사도
def is_same_emotion_batch(originals, candidates, labels):
inputs = tokenizer_cls(candidates, padding=True, truncation=True, return_tensors="pt").to(DEVICE)
with torch.no_grad():
probs = F.softmax(model_cls(**inputs).logits, dim=-1)
pred_labels = torch.argmax(probs, dim=-1).cpu().tolist()
return [pred_labels[i] == labels[i] for i in range(len(labels))]
def remove_duplicates(texts, threshold=0.95):
if len(texts) <= 1:
return texts
vectorizer = TfidfVectorizer().fit_transform(texts)
sim_matrix = cosine_similarity(vectorizer)
keep = []
for i in range(len(texts)):
if not any(sim_matrix[i][j] > threshold for j in keep):
keep.append(i)
return [texts[i] for i in keep]
# =========================
# 증강 루프 (배치 최적화)
# =========================
augmented_data = []
minority_texts = minority_df["review"].tolist()
minority_labels = minority_df["label"].tolist()
for i in tqdm(range(0, len(minority_texts), BATCH_SIZE_LLM)):
batch_texts = minority_texts[i:i+BATCH_SIZE_LLM]
batch_labels = minority_labels[i:i+BATCH_SIZE_LLM]
# 1. LLM으로 paraphrase 생성
batch_paraphrases = generate_paraphrases_batch(batch_texts, num_return=2)
for j, orig in enumerate(batch_texts):
candidates = batch_paraphrases[j]
labels = [batch_labels[j]] * len(candidates)
# 2. 의미 유사도 검사
sim_mask = is_similar_batch([orig]*len(candidates), candidates)
# 3. 감정 일관성 검사
emotion_mask = is_same_emotion_batch([orig]*len(candidates), candidates, labels)
# 4. 필터링
filtered = [c for k, c in enumerate(candidates) if sim_mask[k] and emotion_mask[k]]
# 5. 중복 제거
filtered = remove_duplicates(filtered)
# 6. 저장
for t in filtered:
augmented_data.append({"review": t, "label": batch_labels[j]})
aug_df = pd.DataFrame(augmented_data)
aug_df.to_csv("augmented_data_batch.csv", index=False)
- 유의할 점으로는 Back-Translation, LLM 증강 모두 모델을 통해 아웃풋을 뽑아내는 것이기 때문에 규모가 있는 모델을 사용하며, 몇 만 건 이상으로 증강을 하고자 한다면 꽤 많은 리소스(GPU)를 사용해야 빠르게 증강을 할 수 있다
- 컴퓨팅 리소스가 받쳐주지 않는다면 정말 하루종일 증강하는데만 서버를 돌려야...
- 16,000건 Back-Translation을 적용하는데 6시간 정도 걸렸다
각 텍스트마다 라벨에 대한 확률값을 이용해 모델이 데이터셋에 대해 얼마나 예측을 잘하고 못하는지를 구별해낼 수 있었다
확률값이라는 수치를 통해 이렇게 파생적으로 분석과 여러 액션들을 취해볼 수 있다니 꽤 흥미로웠다
Hard Case에 대해서 더 심도있는 분석을 진행할 수 있었으면 좋았을텐데 이 부분에서 막혔다
분석을 통해 인사이트를 뽑아내야 뭔가를 더 해볼 걸 찾을텐데 텍스트 분석에 대해서는 정말 기초적인 방법들 밖에 떠오르지 않아 참 아쉬웠다
지금은 태스크가 비교적 간단한 분류라서 이렇게 사용 가능하지만 실제 LLM을 이용해 문장을 생성하는 경우에는 원하는 목적과 다른데 유사해보이는 문장들을 핸들링하는 것이 중요하다고 하다
아래 글도 나중에 참고할 겸 저장
https://sjkoding.tistory.com/102
[LLM] Text Embedding모델 파인튜닝을 위한 Hard Negative Mining 방법론 핵심 정리
마지막 포스팅 이후 어느덧 5개월의 시간이 흘렀는데, 사실 이 사이에 회사 이직과 적응을 하느랴 블로그를 신경쓰지 못했습니다.기존에는 LLM 챗봇 구축을 위한 서비스를 개발했다면, 현재는 RAG
sjkoding.tistory.com
'AI' 카테고리의 다른 글
| [Object Detection] Fast R-CNN 살펴보기 (0) | 2025.12.01 |
|---|---|
| [Object Detection] R-CNN 살펴보기 (+SPPNet) (0) | 2025.11.27 |
| 텍스트 feature vector 살펴보기 (0) | 2025.10.29 |
| VGGNet (ICLR 2015) 요약 및 리뷰 (0) | 2024.01.29 |

